


Boom delle assunzioni con l’AI: il 90% delle aziende USA la userà entro il 2029
17 Marzo 2025 - 5 minuti


17 Giugno 2025
Apple ha pubblicato un nuovo studio intitolato The Illusion of Thinking poco prima del WWDC 2025. Il paper di Apple sull’AI si concentra su una categoria di modelli linguistici definiti Large Reasoning Models (LRMs), progettati per emulare processi di pensiero articolati.
Tra i modelli testati: Claude 3.7 Sonnet Thinking, OpenAI o1 e o3, DeepSeek R1 e Google Gemini Flash Thinking.
Per testarne le capacità, i ricercatori hanno utilizzato puzzle logici classici come la Torre di Hanoi, il problema del traghettamento (volpe, gallina e grano – in Italia, lupo, capra e cavoli), puzzle con salti di pedine e costruzioni con blocchi.
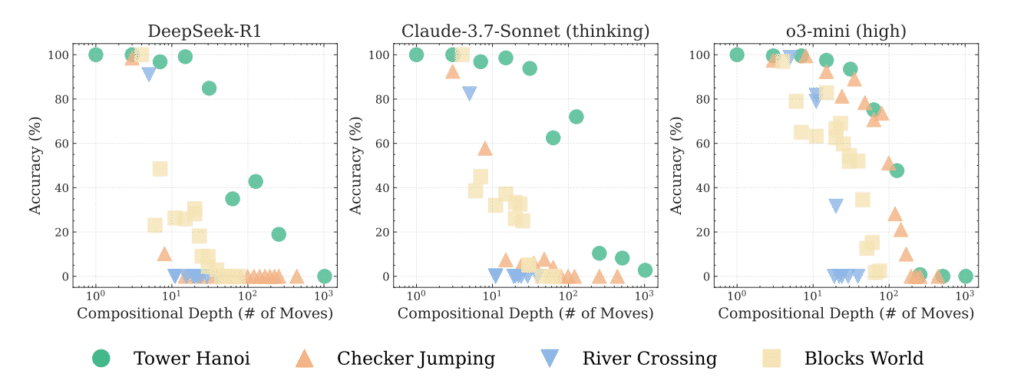
Il principio è semplice: aumentare progressivamente la complessità mantenendo una struttura logica invariata, in modo da verificare la tenuta del ragionamento.
I risultati sono sorprendenti e, in un certo senso, inquietanti: tutti i modelli crollano completamente oltre una soglia critica di difficoltà.
LEGGI ANCHE: 1 miliardo e mezzo di persone usa la ricerca di Google con intelligenza artificiale ogni mese
I ricercatori hanno osservato un comportamento paradossale: man mano che i puzzle diventano più complessi, i modelli iniziano a dedicare meno sforzo al ragionamento.
In gergo tecnico, si riduce l’impiego di thinking tokens, ovvero delle risorse allocate internamente al processo di riflessione del modello.
Nel paper di Apple sull’AI si legge che, proprio quando il problema richiederebbe uno sforzo maggiore, l’AI tende a “gettare la spugna”.
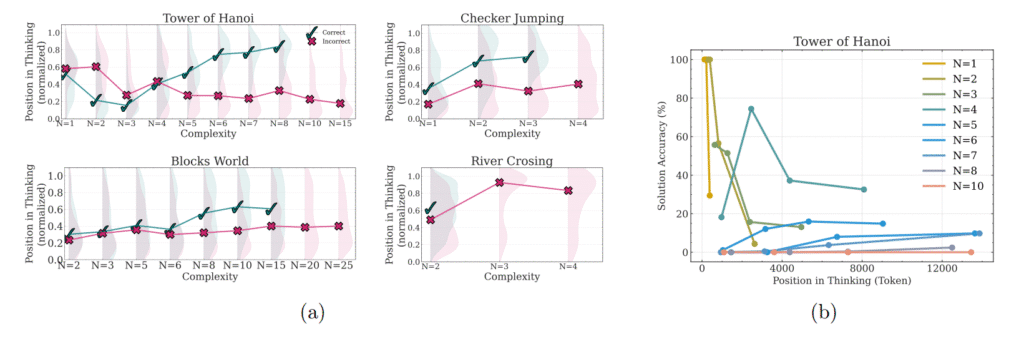
Il punto di collasso è ben identificabile: ad esempio, Claude 3.7 smette di funzionare già con il quinto disco nella Torre di Hanoi, mentre altri modelli vanno in tilt con incrementi minimi di difficoltà. Questo comportamento sembra indicare una debolezza strutturale nei modelli basati su scaling computazionale.
Lo studio ha individuato tre regimi di prestazione distinti nei LRMs:
Anche aumentando la potenza computazionale e l’allocazione di token, la prestazione non migliora, indicando che non è un problema di risorse, ma di struttura cognitiva interna al modello.
Il risultato di questo studio rappresenta un campanello d’allarme per chi, nell’industria tech, sostiene che l’Artificial General Intelligence (AGI) sia vicina.
Il paper di Apple sull’AI sembra suggerire che, al di là delle apparenze, i modelli non “pensano” davvero, ma imitano pattern di ragionamento finché la struttura non diventa troppo complessa.
Il titolo del paper, The Illusion of Thinking, non è scelto a caso: rappresenta una vera e propria accusa all’attuale paradigma di valutazione dell’AI, che spesso si basa sull’accuratezza finale della risposta, ignorando come quella risposta è stata ottenuta.
Apple, invece, propone un approccio più critico e qualitativo, concentrandosi sulla traccia del ragionamento, non solo sul risultato.
A differenza di molti test standardizzati su benchmark matematici o di codice, Apple ha costruito un set di ambienti controllabili, in cui ogni puzzle mantiene una logica coerente e scalabile.
Questo permette di isolare l’effetto della complessità composizionale e analizzare come si struttura il pensiero del modello.
Il team ha scoperto che i modelli spesso non applicano algoritmi espliciti e tendono a ragionare in modo incoerente anche tra puzzle simili.
Questo solleva una questione cruciale: se un modello non riesce a generalizzare un metodo di soluzione tra due problemi simili, può davvero essere definito “intelligente”?
LEGGI ANCHE: Meta investe 10 miliardi su Scale AI per potenziare la sua AI
Nel panorama dell’intelligenza artificiale, Apple ha adottato una strategia atipica. Mentre aziende come Google e Samsung hanno trasformato i loro device in veri e propri hub AI-first, Apple ha introdotto funzionalità AI in modo più contenuto, e solo recentemente, con Apple Intelligence.
Alla luce del paper di Apple sull’AI, questa scelta appare strategica: Apple ha probabilmente riconosciuto i limiti attuali dei modelli linguistici, decidendo di investire in un’AI più etica, trasparente e comprensibile.
Questo potrebbe spiegare il motivo per cui, nonostante la pressione del mercato, Apple non ha abbracciato totalmente la moda dell’AI generativa integrata nei dispositivi.
Infine, il messaggio implicito del paper di Apple sull’AI è una chiamata all’onestà. Non basta affermare che un modello funziona perché risponde correttamente a un certo numero di problemi.
Serve capire cosa c’è dietro quelle risposte, come vengono costruite, quanto sono generalizzabili e soprattutto quanto possiamo fidarci.
È possibile che la prossima evoluzione dell’AI non venga dall’aggiunta di parametri, token o potenza computazionale, ma da una riflessione filosofica e metodologica su come valutiamo l’intelligenza. Apple, con questo studio, apre una nuova strada: meno hype, più verità.
Potrebbe interessarti anche
Potrebbe interessarti anche
Corsi, articoli, eventi: il mondo Ninja è ricco di risorse e di appuntamenti da non perdere.
Please confirm you want to block this member.
You will no longer be able to:
Please allow a few minutes for this process to complete.